Yield Curve Calibration from Rates¶
This tutorial calibrates two short-rate models, the VasicekCurve and the CIRCurve, to a panel of historical US Treasury yields by maximum likelihood. Both treat the short rate as a latent state and the yields as noisy observations of it, but they need different filters: Vasicek is linear-Gaussian and uses the exact KalmanFilter, while CIR has a state-dependent variance and uses the UnscentedKalmanFilter.
For the mechanics of the filters themselves, see the Kalman Filter theory page.
The idea¶
A short-rate model never observes its state directly: what we observe at each date is a cross section of yields. Treating the short rate as a latent state and the yields as noisy observations of it turns calibration into a state-space estimation problem.
At each date every yield is affine in the short rate, so the observation is linear in both models. The filter computes the Gaussian log-likelihood of the observed panel, and the calibrator maximises it over \((\kappa, \theta, \sigma, h)\), where \(h\) is the observation noise standard deviation.
Fetching the data¶
FederalReserve.yield_curves
returns the daily Treasury par-yield panel, indexed by date with one column per
tenor and rates as decimals. The cached_df helper stores the result as a
parquet file so repeated runs do not hit the network.
The calibration assumes a uniform time step, while the raw data is sampled on business days. Resampling to weekly Wednesdays with the average yield over each week gives an evenly spaced panel.
Vasicek: the exact Kalman filter¶
The Vasicek short rate is an Ornstein-Uhlenbeck process. Over a uniform time step its dynamics reduce to a Gaussian AR(1) with a constant innovation variance, and each yield is affine in the short rate. The calibrate_historical_rates method documents these equations.
Because the model is fully linear-Gaussian, the exact Kalman filter gives the exact log-likelihood. One full Kalman pass over the panel is performed per optimiser iteration.
CIR: why the unscented filter¶
The CIR short rate is a square-root diffusion, \(dr_t = \kappa(\theta - r_t)\,dt + \sigma\sqrt{r_t}\,dW_t\). Its conditional mean is still linear in the previous state, but its conditional variance depends on the state:
The exact Kalman filter assumes a constant process-noise covariance, so it cannot represent this heteroskedasticity. The unscented Kalman filter only needs the conditional mean and covariance of the transition, which it propagates through sigma points, so the state-dependent variance drops straight in. The [CIRStateSpaceModel][quantflow.rates.cir.CIRStateSpaceModel] supplies those moments and the affine observation, and calibrate_historical_rates runs the unscented filter inside the same maximum-likelihood loop.
Calibrating¶
For both models,
calibrate_historical_rates_dataframe
parses the tenor columns into times to maturity, infers the time step from the
index, converts the par yields to continuously compounded rates (here
frequency=2 for semiannual compounding), and runs the maximum-likelihood fit.
The fitted parameters and the final filtered short rate are returned on each calibrated curve:
Vasicek (Kalman filter)
{
"curve_type": "vasicek_curve",
"rate": "0.0403982712",
"kappa": "0.2634535836",
"theta": "0.0718450873",
"sigma": "0.0613356808"
}
CIR (unscented Kalman filter)
{
"curve_type": "cir_curve",
"rate": "0.0370463245",
"kappa": "0.0731213397",
"theta": "0.0686465956",
"sigma": "0.1001951199"
}
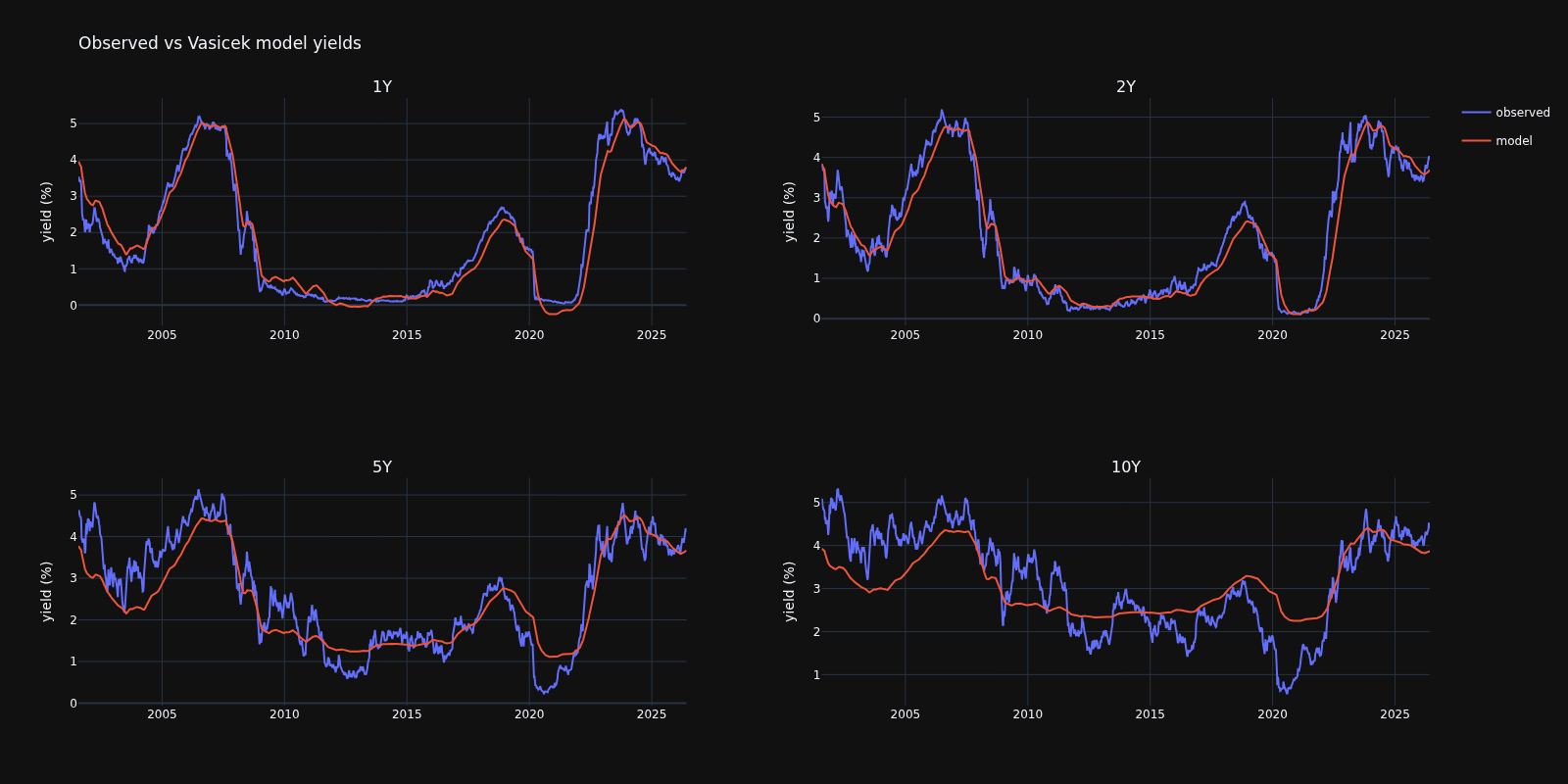
Model versus observed through time¶
The fit is a time-series fit, so the right check is whether each model tracks the
history of every tenor. Both calibrators expose a filtered_short_rate path
(Vasicek,
CIR), from which
each tenor's model-implied yield is reconstructed through the affine yield
relation and plotted against its observed history.
Both single-factor models track the short and intermediate tenors (1Y, 2Y) closely and are smoother than the data at the long end (5Y, 10Y): one mean-reverting factor cannot capture the independent variation of the long end. The two fits stay close in this rate regime, the difference being the CIR volatility that scales with the level of rates.
Code¶
import asyncio
from datetime import timedelta
from decimal import Decimal
import numpy as np
import pandas as pd
import plotly.graph_objects as go
from plotly.subplots import make_subplots
from docs.examples._utils import assets_path, cached_df
from quantflow.data.fed import FederalReserve
from quantflow.rates.calibration import tenor_to_years
from quantflow.rates.cir import CIRCurve
from quantflow.rates.vasicek import VasicekCurve
@cached_df(ttl=timedelta(days=1))
def fed_yield_curves() -> pd.DataFrame:
async def fetch() -> pd.DataFrame:
async with FederalReserve() as fed:
return await fed.yield_curves()
return asyncio.run(fetch())
# daily par-yield panel from the Federal Reserve (cached for a day)
df = fed_yield_curves()
# weekly panel (uniform 7-day step) using the average yield over each week
weekly = df.resample("W-WED").mean().dropna()
ttm = np.array([tenor_to_years(c) for c in weekly.columns])
# Vasicek: linear-Gaussian, fitted with the exact Kalman filter
vasicek_cal = VasicekCurve().calibrator()
vasicek = vasicek_cal.calibrate_historical_rates_dataframe(weekly, frequency=2)
print("Vasicek (Kalman filter)")
print(vasicek.model_dump_json(indent=2, exclude={"ref_date"}))
# CIR: state-dependent variance, fitted with the unscented Kalman filter
cir_cal = CIRCurve().calibrator()
cir = cir_cal.calibrate_historical_rates_dataframe(weekly, frequency=2)
print("CIR (unscented Kalman filter)")
print(cir.model_dump_json(indent=2, exclude={"ref_date"}))
# model-implied semi-annual rates at each date from the filtered short rate paths
va_short = vasicek_cal.filtered_short_rate
cir_short = cir_cal.filtered_short_rate
va_model = np.zeros((len(va_short), len(ttm)))
cir_model = np.zeros((len(cir_short), len(ttm)))
for t in range(len(va_short)):
vasicek.rate = Decimal(str(float(va_short[t])))
va_model[t] = np.asarray(vasicek.rates(ttm), dtype=float)
cir.rate = Decimal(str(float(cir_short[t])))
cir_model[t] = np.asarray(cir.rates(ttm), dtype=float)
# observed (par -> continuous) and both model yields per tenor, over time
tenors = ["1Y", "2Y", "5Y", "10Y"]
colours = dict(observed="#636efa", Vasicek="#ef553b", CIR="#00cc96")
fig = make_subplots(rows=2, cols=2, subplot_titles=tenors)
for k, tenor in enumerate(tenors):
i = weekly.columns.get_loc(tenor)
row, col = k // 2 + 1, k % 2 + 1
series = {
"observed": 2.0 * np.log1p(weekly[tenor].to_numpy() / 2.0) * 100,
"Vasicek": va_model[:, i] * 100,
"CIR": cir_model[:, i] * 100,
}
for name, values in series.items():
fig.add_trace(
go.Scatter(
x=weekly.index,
y=values,
name=name,
legendgroup=name,
showlegend=k == 0,
line=dict(color=colours[name]),
),
row=row,
col=col,
)
fig.update_layout(title="Observed vs Vasicek and CIR model yields")
fig.update_yaxes(title_text="yield (%)")
fig.write_image(assets_path("rates_kalman.png"), width=1600, height=800)